Using conditional COUNT(*)s
The Problem
Whilst recently working with historic financial data, I ran across a situation that needed an aggregate view of transactional data grouped by a certain set of attributes in order to backfill some missing aggregate data sets. In front of me, I had transactional data from time immemorial along with a series of pre-built (validated) historic aggregates which had been created from a different (but now unknown) process.
My mission then, was to understand how this source transactional data must be aggregated so that it could be compared against the sets of pre-built aggregate data. Once I validated the process, I could (re)populate the missing aggregate tables in confidence.
The source transactional table (simplified for brevity) consisted of: Transaction_Date, Credit_Card_Type, Transaction_Type, and Sales_Value.
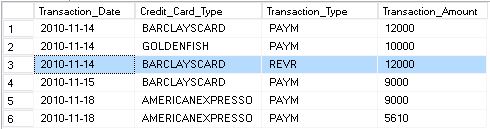
The aggregated destination table consisted of: Transaction_YYMM, Credit_Card, Number_Of_Sales, and Sales_Value
The task in itself appeared relatively trivial and looked to require a grouping on Transaction_YYMM (a calculated field from Transaction_Date) and Credit_Card_Type, with Number_Of_Sales being a simple COUNT(*) of each transaction. Therefore Sales_Value appeared to be a simple SUM of the transaction Sales_Value -easy right!
If we run the following query:
SELECT
CAST(FORMAT(Transaction_Date, 'yyyy-MM') AS VARCHAR(max)) AS 'Transaction_YYMM',
Credit_Card_Type,
COUNT(*) AS 'Number_Of_Sales',
SUM(Transaction_Amount) AS 'Sales_Value'
FROM #Transactions
GROUP BY
CAST(FORMAT(Transaction_Date, 'yyyy-MM') AS VARCHAR(max)),
Credit_Card_Type
GO
We get the following results:

When I came to compare the results against aggregated data, I noticed that the values were off and it became fairly obvious that the transactional data also contained refunds and rebates (positive values but logically reflected as negative by the Transaction_Type status) and these were not just causing inaccuracies for the SUM on Sales_Value, but were also causing the COUNT for Number_Of_Sales to be wrong. In other words, refunds and rebates must be removed from the SUM total and not aggregated in the Number_Of_Sales columns. Now at this stage, you might be thinking that we can do this by a simple WHERE clause to filter them from the aggregates, but not only is it wrong to “throw away” data, I realised that my target tables also contained aggregate columns for refunds and rebates.
Therefore our target table now consists of the following columns: Transaction_Date, Credit_Card_Type, Transaction_Type, and Sales_Value, Number_Of_Refunds, Refund_Value
Solving the conditional COUNT
In order to achieve this goal from our source data, it is obvious that we need a conditional statement to aggregate the payment data only within the payment columns and aggregate the refund data only in the refund columns. Implementing this logic within the SUM statement was easy and was as follows:
SELECT ...
SUM(CASE WHEN Transaction_Type IN ('PAYM') THEN Transaction_Amount
ELSE 0 END) AS 'Sales_Value'
FROM ...
In the function above, SUM will simply aggregate all Transaction_Amount(s) if they are of Transaction_Type PAYM, otherwise it will consider that specific value as zero (thereby excluding it from the aggregation). When it came to the COUNT statement, things were not quite so obvious. I confess to mostly using COUNT in its COUNT(*) guise in the past, but imagine my surprise after browsing the online pages for the COUNT statement, I notice the expression keyword (see below).
COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
If expressions are also permitted inside the COUNT function (like SUM) then perhaps I can do something similar to the way I calculated the conditional SUM?
I tried the following function call for that aggregation:
SELECT ...
COUNT(CASE WHEN Transaction_Type IN ('PAYM') THEN 1
ELSE 0 END) AS 'Number_Of_Sales'
FROM ...
And while this code code ran, it did not make any difference to the counts returned (let’s demonstrate this using the full code for payments and refunds):
SELECT
CAST(FORMAT(Transaction_Date, 'yyyy-MM') AS VARCHAR(7)) AS 'Transaction_YYMM',
Credit_Card_Type,
COUNT(CASE WHEN Transaction_Type IN ('PAYM') THEN 1
ELSE 0 END) AS 'Number_Of_Sales',
SUM(CASE WHEN Transaction_Type IN ('PAYM') THEN Transaction_Amount
ELSE 0 END) AS 'Sales_Value',
COUNT(CASE WHEN Transaction_Type IN ('REVR') THEN 1
ELSE 0 END) AS 'Number_Of_Refunds',
SUM(CASE WHEN Transaction_Type IN ('REVR') THEN Transaction_Amount
ELSE 0 END) AS 'Refund_Value'
FROM #Transactions
GROUP BY
CAST(FORMAT(Transaction_Date, 'yyyy-MM') AS VARCHAR(7)),
Credit_Card_Type
GO
We get the following results:

We can quite clearly see that this time the Sales_Value and Refund_Value aggregates (using SUM) are correct (see the difference for BARCLAYSCARD data), but the counts are obviously wrong -in fact the “conditional COUNT” appears to just be ignoring the expression.
However I realised that I could use SUM instead of COUNT as a workaround to this problem as follows:
SELECT
CAST(FORMAT(Transaction_Date, 'yyyy-MM') AS VARCHAR(7)) AS 'Transaction_YYMM',
Credit_Card_Type,
SUM(CASE WHEN Transaction_Type IN ('PAYM') THEN 1
ELSE 0 END) AS 'Number_Of_Sales',
SUM(CASE WHEN Transaction_Type IN ('PAYM') THEN Transaction_Amount
ELSE 0 END) AS 'Sales_Value',
SUM(CASE WHEN Transaction_Type IN ('REVR') THEN 1
ELSE 0 END) AS 'Number_Of_Refunds',
SUM(CASE WHEN Transaction_Type IN ('REVR') THEN Transaction_Amount
ELSE 0 END) AS 'Refund_Value'
FROM #Transactions
GROUP BY
CAST(FORMAT(Transaction_Date, 'yyyy-MM') AS VARCHAR(7)),
Credit_Card_Type
GO
And this time we get the results we were looking for:

It was only after getting a working solution that I revisited using a conditional count to perform the aggregation. After thinking a little more about what COUNT is actually doing (increments a “count for every item in a group”), my expression logic didn’t quite make sense. In that case COUNT was incrementing regardless of whether a 1 or 0 was returned, so instead of returning a 0, this time I decided to return a NULL. The code fragment is as follows:
SELECT ...
COUNT(CASE WHEN Transaction_Type IN ('PAYM') THEN 1
ELSE NULL END) AS 'Number_Of_Sales'
FROM ...
The results were a success! However we are not entirely done since this code could be refactored further to remove the ELSE clause since a NULL would be implicitly returned if the CASE statement did not find a match.
The final solution is as follows:
SELECT
CAST(FORMAT(Transaction_Date, 'yyyy-MM') AS VARCHAR(7)) AS 'Transaction_YYMM',
Credit_Card_Type,
COUNT(CASE WHEN Transaction_Type IN ('PAYM') THEN 1 END) AS 'Number_Of_Sales',
SUM(CASE WHEN Transaction_Type IN ('PAYM') THEN Transaction_Amount
ELSE 0 END) AS 'Sales_Value',
COUNT(CASE WHEN Transaction_Type IN ('REVR') THEN 1 END) AS 'Number_Of_Refunds',
SUM(CASE WHEN Transaction_Type IN ('REVR') THEN Transaction_Amount
ELSE 0 END) AS 'Refund_Value'
FROM #Transactions
GROUP BY
CAST(FORMAT(Transaction_Date, 'yyyy-MM') AS VARCHAR(7)),
Credit_Card_Type
GO
And the results are identical as before.
Should we use SUM or COUNT?
While my head tells me that using the COUNT operator to perform conditional counts is the purest (and most logical) solution, I personally think it is less readable (despite being less code) for the layman and instead quite like the SUM approach since it is self-explanatory.
Furthermore, while the query plans of both approaches appear to be identical upon first glance, I noticed that the COUNT approach had (very) slightly higher query costs. I haven’t compared execution times or other performance metrics, but I suspect there will be little difference between them. In other words, use whatever works for you!
Summary
After using the COUNT operator for well over 20 years, this exercise has proved to me that there are still functional nuances lurking that will bite me from time to time. This is not a SQL Server problem, it’s just a ME problem (in not always understanding operations correctly)!
If you would like to try this out yourself I have provided the setup code below:
CREATE TABLE #Transactions
(Transaction_Date DATE,
Credit_Card_Type VARCHAR(16),
Transaction_Type CHAR(4),
Transaction_Amount INT)
GO
INSERT INTO #Transactions VALUES
('2010-11-14',
'BARCLAYSCARD',
'PAYM',
12000
),
('2010-11-14',
'GOLDENFISH',
'PAYM',
10000
),
('2010-11-14',
'BARCLAYSCARD',
'REVR',
12000
),
('2010-11-15',
'BARCLAYSCARD',
'PAYM',
9000
),
('2010-11-18',
'AMERICANEXPRESSO',
'PAYM',
9000
),
('2010-11-18',
'AMERICANEXPRESSO',
'PAYM',
5610
)
GO